import pandas as pd
my_list = [('a', 2, 3),
('b', 5, 6),
('c', 8, 9),
('a', 2, 3),
('b', 5, 6),
('c', 8, 9)]
col_name = ['col1', 'col2', 'col3']
#-- pd
dp = pd.DataFrame(my_list,columns=col_name)
dp
#-- ps
ds = spark.createDataFrame(my_list,schema=col_name
import pyspark.sql.functions as F
#-- pd
dp['concat'] = dp.apply(lambda x:'%s%s'%(x['col1'],x['col2']),axis=1)
dp
#-- ps
ds.withColumn('concat',F.concat('col1','col2')).show()
# 5.3.14 GroupBy
#-- pd
dp.groupby(['col1']).agg({'col2':'min','col3':'mean'})
#-- ps
ds.groupBy(['col1']).agg({'col2': 'min', 'col3': 'avg'}).show()
# 5.3.15 피벗(Pivot)
import numpy as np
#-- pd
pd.pivot_table(dp, values='col3', index='col1', columns='col2', aggfunc=np.sum)
#-- ps
ds.groupBy(['col1']).pivot('col2').sum('col3').show()
# 5.3.16 Window
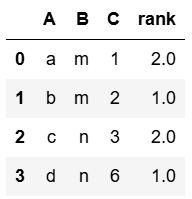
d = {'A':['a','b','c','d'],'B':['m','m','n','n'],'C':[1,2,3,6]}
#-- pd
dp = pd.DataFrame(d)
dp
#-- ps
ds = spark.createDataFrame(dp)
ds.show()
#-- pd
dp['rank'] = dp.groupby('B')['C'].rank('dense',ascending=False)
dp
#-- ps
from pyspark.sql.window import Window
w = Window.partitionBy('B').orderBy(ds.C.desc())
ds = ds.withColumn('rank',F.rank().over(w))
ds.show()
# 5.3.17 rank vs dense_rank
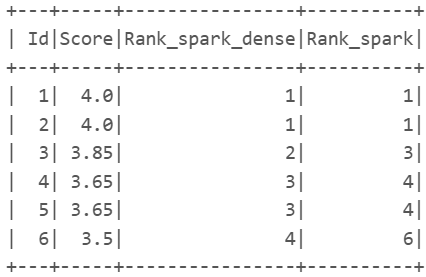
d ={'Id':[1,2,3,4,5,6],
'Score': [4.00, 4.00, 3.85, 3.65, 3.65, 3.50]}
data = pd.DataFrame(d)
dp = data.copy()
dp
ds = spark.createDataFrame(data)
#-- ps
dp['Rank_dense'] = dp['Score'].rank(method='dense',ascending=False)
dp['Rank'] = dp['Score'].rank(method='min',ascending=False)
dp
#-- ps
import pyspark.sql.functions as F
from pyspark.sql.window import Window
w = Window.orderBy(ds.Score.desc())
ds = ds.withColumn('Rank_spark_dense',F.dense_rank().over(w)) ds = ds.withColumn('Rank_spark',F.rank().over(w))
ds.show()