# pd (판다스)
import pandas as pd
# import pyspark.pandas as ps
my_list = [[230.1, 37.8, 69.2, 22.1], [44.5, 39.3, 45.1, 10.4],[17.2, 45.9, 69.3, 9.3],[151.5, 41.3, 58.5, 18.5]]
col_name = ['TV', 'Radio', 'Newspaper', 'Sales']
#-- pd --
drop_name = ['Newspaper', 'Sales']
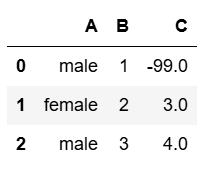
dp = pd.DataFrame(my_list, columns= col_name)
dp.drop(drop_name, axis=1).head(4)
 |
# PS (spark)
import pyspark.pandas as ps
spark = SparkSession .builder \
.appName("Python Spark create RDD example") \
.config("spark.some.config.option", "some-value") \
.getOrCreate()
ds = spark.read.format("csv").load("/FileStore/tables/Advertising.csv", header=True)
#-- ps --
drop_name = ['Newspaper', 'Sales']
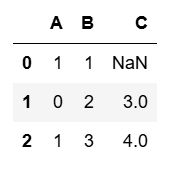
ds.drop(*drop_name).show(4) |
5.3.10 추출(Filter)
# pd (판다스)
import pyspark.pandas as ps
from pyspark.sql import SparkSession
# 주의 !! databricks에서 pandas의 csv파일 read하려면 로컬에 파일이 있어야만 가능하기 때문에 교재명령은 불가능
# dp = pd.read_csv('Advertising.csv') 교재예시
# 그래서 편법으로 아래와 같이 사용함
import pandas as pd
df_pandas = spark.read.format("csv").load("/FileStore/tables/Advertising.csv", header=True).toPandas()
df_pandas.head(4)
df_pandas['TV'] = df_pandas['TV'].astype(float)
df_pandas['Radio'] = df_pandas['Radio'].astype(float)
df_pandas['Newspaper'] = df_pandas['Newspaper'].astype(float)
df_pandas['Sales'] = df_pandas['Sales'].astype(float)
# df_pandas.dtypes
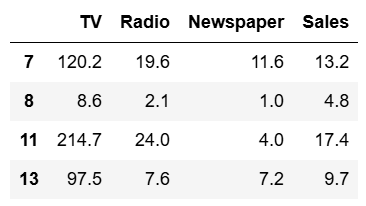
df_pandas[df_pandas.Newspaper<20].head(4)
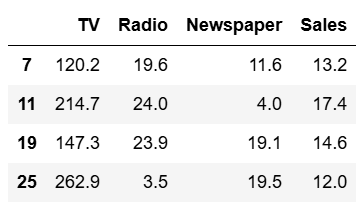
df_pandas[(df_pandas.Newspaper<20)&(df_pandas.TV>100)].head(4)
 |
 |
# PS (spark)
ds = spark.read.format("csv").load("/FileStore/tables/Advertising.csv", header=True)
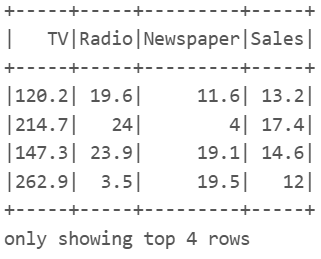
ds[ds.Newspaper<20].show(4)
ds[(ds.Newspaper<20)&(ds.TV>100)].show(4)
 |
 |
5.3.11 새 컬럼 추가하기
#-- df_pandas
df_pandas['tv_norm'] = df_pandas.TV/sum(df_pandas.TV)
df_pandas.head(4)
#-- ps
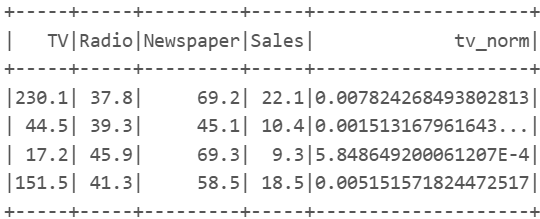
import pyspark.sql.functions as F
ds = spark.read.format("csv").load("/FileStore/tables/Advertising.csv", header=True)
ds.withColumn('tv_norm', ds.TV/ds.groupBy().agg(F.sum("TV")).collect()[0][0]).show(4)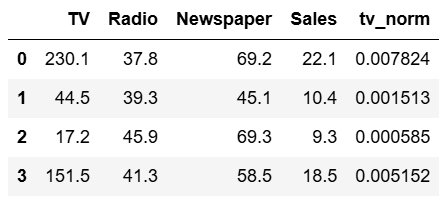 |
 |
#-- df_pandas
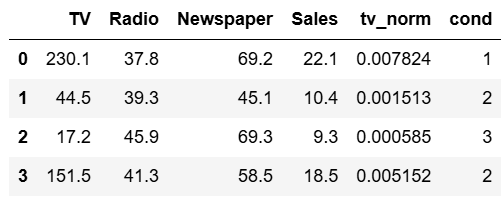
df_pandas['cond'] = df_pandas.apply(lambda A: 1 if((A.TV>100)&(A.Radio<40)) else 2 if(A.Sales> 10) else 3,axis=1)
df_pandas.head(4)
#-- ps
ds.withColumn('cond', F.when((ds.TV>100)&(ds.Radio<40),1)\
.when(ds.Sales>10, 2)\
.otherwise(3)).show(4)
 |
 |
#-- df_pandas
import numpy as np
df_pandas['log_tv'] = np.log(df_pandas.TV)
df_pandas.head(4)
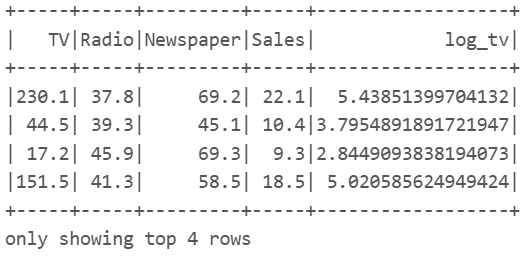
#-- ps
import pyspark.sql.functions as F
ds.withColumn('log_tv', F.log(ds.TV)).show(4)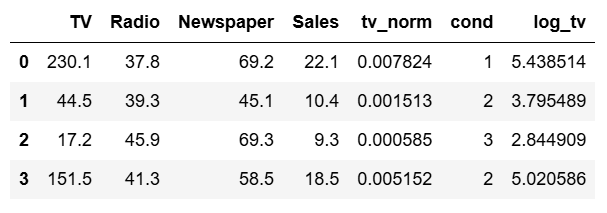 |
 |
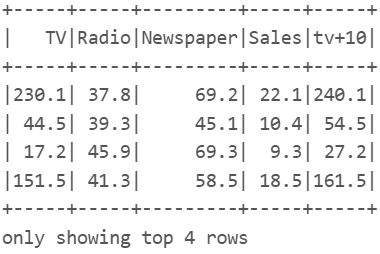
#-- df_pandas
df_pandas['tv+10'] = df_pandas.TV.apply(lambda x: x+10)
df_pandas.head(4)
#-- ps
ds.withColumn('tv+10', ds.TV+10).show(4)
 |
 |
'Python > Spark' 카테고리의 다른 글
| AI Agent 구축 (2) | 2025.04.30 |
|---|---|
| 5.3.13 열 결합하기(Concat) (0) | 2025.01.08 |
| 5.3.11 조인(Join) (0) | 2025.01.07 |
| 5.3.6 널(Null) 값 채우기 (0) | 2024.12.25 |
| 5.1 RDD 생성 (0) | 2024.12.15 |